在当今这个数据驱动的时代,“大数据”已成为一个无处不在的热门词汇。无论你是技术爱好者、企业管理者,还是希望转行进入数据领域的新手,理解大数据的基础概念都至关重要。入门大数据,并非意味着你必须立即掌握复杂的技术栈,而是先建立对核心概念和生态的整体认知。以下是每一位大数据初学者都需要了解的5件基础要事。
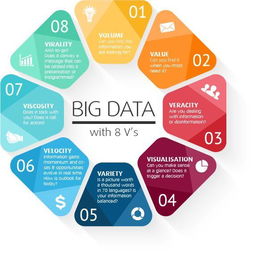
1. 理解大数据的核心“5V”特征
大数据的定义远不止于“数据量很大”。它通常由五个核心特征来界定,即“5V”:
Volume(大量):数据的规模极其庞大,通常达到TB、PB甚至EB级别,传统工具难以处理。
Velocity(高速):数据产生的速度非常快,需要近乎实时地处理和分析,例如社交媒体流、物联网传感器数据。
Variety(多样):数据格式多样,包括结构化数据(如数据库表格)、半结构化数据(如XML、JSON日志)和非结构化数据(如文本、图片、视频)。
Veracity(真实性/准确性):数据的质量和可信赖度。海量数据中可能存在噪声、不一致和不确定性,确保数据可信是分析的前提。
* Value(价值):这是最终目的。大数据本身并非目的,如何从海量、高速、多样的数据中挖掘出洞察、预测趋势、创造商业价值,才是关键。
理解这“5V”,能帮助你从本质上把握大数据处理所面临的挑战和机遇。
2. 掌握从数据到价值的基本流程
处理大数据并非一蹴而就,它遵循一个清晰的流程管道:
1. 数据采集与存储:需要从各种源头(网站、APP、传感器等)收集数据,并将其存储在可扩展、可靠的存储系统中,如Hadoop HDFS、云对象存储等。
2. 数据处理与集成:对原始数据进行清洗、转换、集成,将其转化为可供分析的格式。这一阶段可能涉及批处理(如使用MapReduce、Spark)或流处理(如使用Flink、Storm)。
3. 数据分析与挖掘:运用统计分析、机器学习、数据挖掘等技术,从处理好的数据中发现模式、关联和洞察。
4. 数据可视化与解释:将分析结果以图表、仪表盘等直观形式呈现,让非技术人员也能理解,并据此做出决策。
了解这个端到端的流程,能让你明白大数据项目中各个环节的角色和所需技术。
3. 熟悉主流的技术生态与工具
大数据领域拥有一个庞大且活跃的开源技术生态。入门时,无需全部精通,但需要对核心组件有所了解:
存储基石:Hadoop HDFS 是分布式文件系统的代表,为海量数据提供存储基础。
计算引擎:Apache Spark 是目前最主流的分布式计算框架,因其内存计算特性,在速度和易用性上远超早期的MapReduce,支持批处理、流处理、机器学习和图计算。
资源管理与调度:Apache Hadoop YARN 和 Kubernetes 负责管理集群资源,调度各项计算任务。
NoSQL数据库:为处理多样、灵活的数据模型而生,如 HBase(列存储)、MongoDB(文档存储)、Cassandra(宽列存储)。
* 消息/流处理:Apache Kafka 是处理实时数据流的消息队列核心,常与 Flink 或 Spark Streaming 配合实现实时分析。
从Hadoop生态到以Spark、Flink为核心的现代架构,了解这些工具的基本定位是构建技术知识地图的第一步。
4. 认识到云计算的关键作用
对于初学者和企业而言,云计算极大地降低了大数据的入门门槛。AWS、Azure、阿里云等主流云平台提供了全面托管的大数据服务(如Amazon EMR、Azure HDInsight),让你无需自行搭建和维护复杂的物理集群,即可按需使用存储、计算和各类分析工具。理解云服务模型(IaaS, PaaS, SaaS)以及如何利用云平台快速开展大数据项目,是现代大数据实践的重要一环。
5. 明确技能发展与学习路径
对于个人学习者,一个清晰的入门路径至关重要:
- 基础先行:扎实掌握 Linux 命令行操作、至少一门编程语言(Python 或 Scala 在大数据领域应用广泛)以及 SQL 知识。
- 核心突破:深入学习和实践 Hadoop 和 Spark 的核心原理与编程。可以从单机伪分布式环境搭建开始,运行简单的WordCount程序,逐步深入。
- 领域深入:根据兴趣方向,选择深入学习 数据仓库/湖仓一体(如Hive)、实时计算(如Flink)、数据挖掘与机器学习(MLlib)等特定领域。
- 项目实践:理论结合实践至关重要。尝试在公共数据集或模拟业务数据上,完成一个从数据采集、处理、分析到可视化的小型端到端项目。
总而言之,大数据入门是一个系统工程。从理解核心概念开始,到把握技术生态,再到结合云平台进行实践,这五件事为你构建了一个坚实的学习框架。记住,关键在于保持好奇,动手实践,循序渐进地在这个充满机遇的领域中探索和成长。